The first time in my life that I realized how important a backup is was the day I lost my precious phone numbers agenda. There were no mobile phones and no internet at that time, and all my contacts’ phone numbers and, in some cases, home addresses too, were in there. It was a tiny yellow and grey agenda, with one page sharing multiple surname initials and I had spent a great deal of effort building it up.
The day I lost it, I cursed myself for not having thought to make a backup copy. But hey, who thinks about backups when you are 10 years old? I was comforted by the fact that half of the people in that agenda were my classmates, the other half being my relatives.
Since that day, I have heard many, many stories about people losing the first picture of their newborn, a production database, or, yes, their contacts list.
When it comes to Postgres, there are several reasons you might want to have a backup. The most common is to be able to restore your data in case you accidentally delete it, or in the case of a media failure rendering the data unreadable.
There are also other reasons you might need a backup, for instance, to export your data from production and import it to another environment where tests or development runs. Combined with some sort of anonymization, that is considered a very best practice to guarantee the quality of your product.
Postgres allows two different kinds of backups, ‘physical’ and ‘logical’. Both serve the same goal of saving the data at a certain point in time, but the two methods differ in concept, execution and they also both have their own pros and cons.
Let’s have a look together.
Physical backup
The Postgres database stores data on the filesystem for persistence. All the data contained in the ‘data’ and in the ‘pg_wal’ (formerly known as ‘pg_xlog’) folders combine to make the database content.
It is possible to recreate the full database just by copying both folders. That is why it is called ‘physical’ because we are actually copying the data from the filesystem.
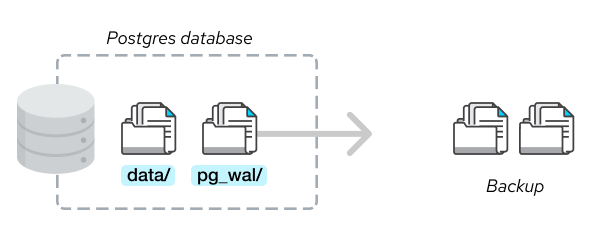
Note that the backup must be restored on the same major server version it was taken. Therefore you cannot take a physical backup on Postgres 12 and restore it to Postgres 13.
There are several techniques to make the backup including rsync, scp, or any of the available tools out there. It is important to keep in mind that the backup created will contain data until the very moment the last bit of data is read.
The most convenient method is to use the pg_basebackup tool provided by PostgreSQL. In order to be able to connect using pg_basebackup, you must be able to connect with superuser or replication privileges.
pg_basebackup will use the replication protocol (the same one used when streaming data to a standby server), therefore max_wal_senders should be set accordingly.
There can be multiple pg_basebackup running at the same time, but it is not recommended to do so because it is a costly operation, and performance issues might occur.
Once a backup is created this way, it can be used also to create a standby host or to feed a Point In Time Recovery. In such cases, you can use the ‘-R’ option, which tells pg_basebackup to also write the configuration directives needed to configure the server as standby, which is very convenient.
Point In Time Recovery allows you to start from a backup and feed your server with additional WAL files created since the backup was taken, in order to bring the database to the desired state at a specific point in time (in the past for us, but in the future from the point of view of when the backup was taken).
PITR comes in handy right after the emergency call, ‘Oops, I dropped a table by accident’. In that case, what you want to do is to retrieve the most recent backup and all the WAL files archived since the backup. With both ingredients and some time, you will be able to recover your data at the very moment before the mistake happened.
Logical backup
Logical backup generates a file with all the SQL instructions needed to restore the data at the moment when the backup command was launched.
It is performed by running the command ‘pg_dump’ followed by the database you want to backup.
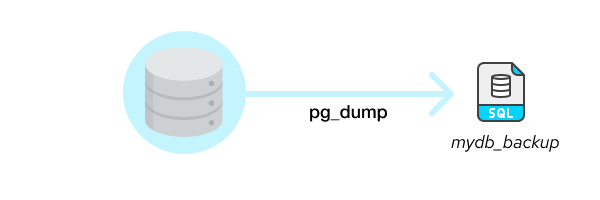
Something like:
pg_dump -h host -p port mydb > mydb_backupThe file ‘mydb_backup’ will contain all the instructions and data to restore ‘mydb’. The default behavior is to create a text file. Other formats can be chosen, which also allow parallelism in order to be more efficient in terms of disk space and time.
Keep in mind that even when written to a text file, a logical backup is usually smaller than the database it has been copied from. That is because indexes are not copied as data (like in the physical backup) but are represented by a single statement ‘CREATE INDEX..’.
The user performing the backup must have all read permissions on the target database. You could also use pg_dump to backup a part of your database, specifying a schema or a table. In contrast to a physical backup, a logical backup can be restored to a server version different from where it was taken.
The backup can be then restored using ‘psql’ only after the target database has been manually created using the ‘CREATE DATABASE’ SQL command or ‘createdb’ utility.
To restore the dump, you can run:
psql mydb < mydb_backupIt is important to keep in mind that since the backup file contains instructions to create objects and fill them with data, it is not idempotent. If you run it twice you will receive errors and, worse, you might end up with duplicated rows.
It is possible to exit on errors, using psql command with ‘--set ON_ERROR_STOP=on’, eg:
psql --set ON_ERROR_STOP=on mydb < mydb_backupIf the dump is taken using the flag ‘-Fc’, then the custom format is used instead of plaintext. In this case, the dump can be restored only using the ‘pg_restore’ command.
Similar to pg_dump, is pg_dumpall, with the difference that pg_dumpall will dump all the databases in the cluster and not only the target database. All the databases available will be dumped, which is very convenient because it is also able to restore the users and all the databases without the need to create them by hand.
Such backup can be restored running:
psql -f mydb_backup postgres # Instead of ‘postgres’ it is also possible to use any existing database as long as you can connect to it.
Only superusers can restore a dump taken using pg_dumpall.
When taking backups, always keep in mind that it is an expensive operation not only in terms of database resources but also from the client-side. Bandwidth or disks might pose speed limits and the backup might take a very long time to be retrieved. If you can, use a machine near the database (eg: in the same LAN), and keep an eye on how it goes, especially to CPU, disk, and bandwidth usage. You do not want to stress too much your database or fill the bandwidth used by your users!
Backups with ElephantSQL
When you create your instances with elephantsql.com, managing backups is really a no-brainer. Just go to your database instance under the ‘Backups’ section and click on ‘Backup now’ or click on ‘Restore’ next to the backup you would like to restore and voila! A logical backup of your database is made available for you.
For paid plans logical backups are automatically taken once a day. And regardless of plan, physical backups are continuously streamed to a secure cloud storage and retained for 30 days. Remember also that here at ElephantSQL we offer a convenient API, a very handy way to schedule your backups and do much more such as restore to a point in time. For instance, in order to restore a backup the only thing you have to do is to make a POST call like:
POST https://api.elephantsql.com/api/backupRead more about this in ElephantSQL API Documentation.